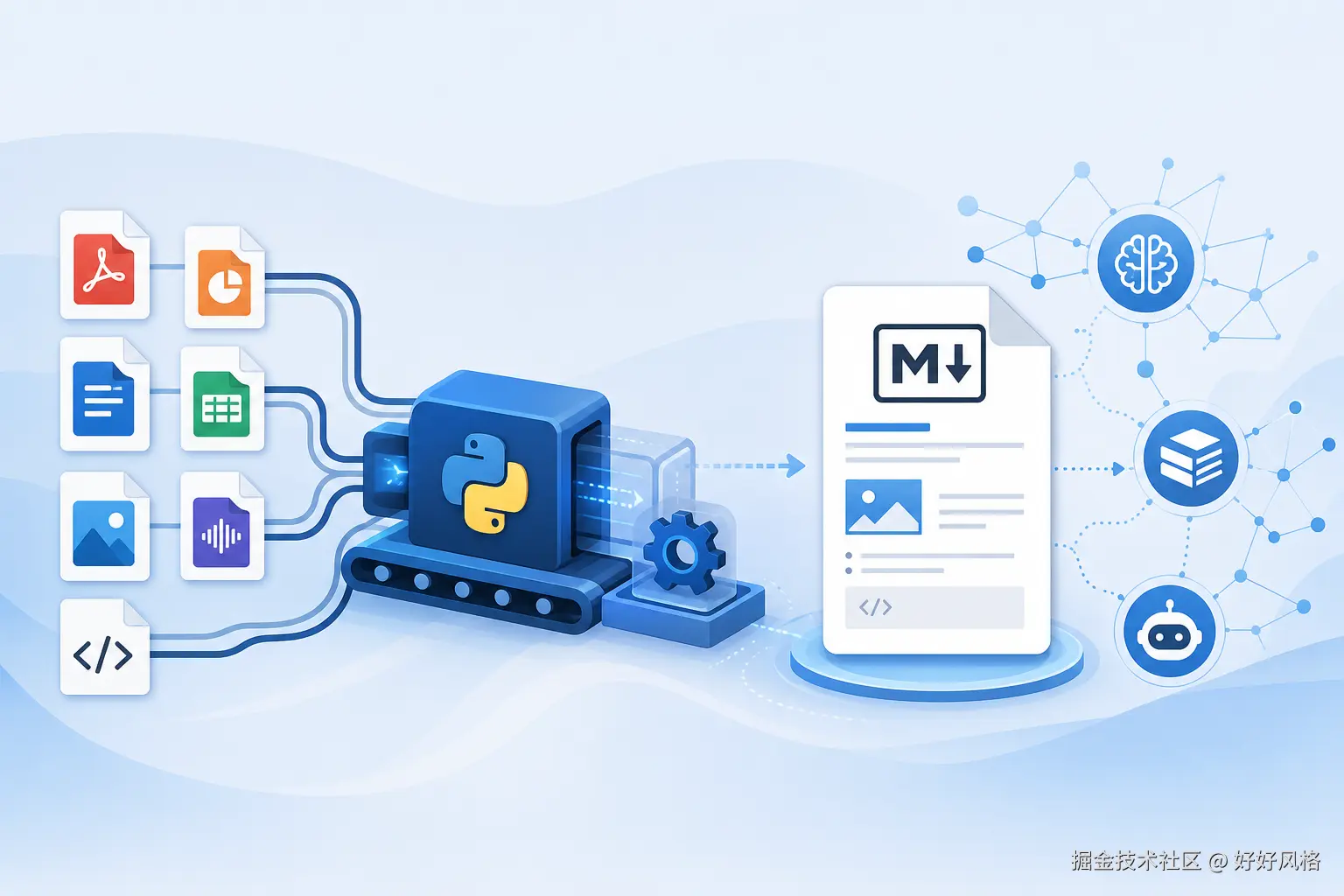
微软这个 14 万星工具,把 PDF、PPT、Excel 都变成大模型爱读的 Markdown
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
一、为什么最近值得看 MarkItDown如果你做过 RAG、知识库、Agent 工具链,应该很熟悉一个尴尬问题:资料本身很多,但格式太乱。 PDF 里有段落和表格,PPT 里有标题和图片,Excel 里有工作表,网页里有链接,ZIP 里还有一堆嵌套文件。真正送进大模型之前,往往要先经历一轮“文档清洗”。 微软开源的 MarkItDown,解决的就是这个前置步骤:把多种文件和内容源转成 Markdown。它不是为了生成漂亮排版,而是为了保留标题、列表、表格、链接等关键信息结构,让后续的大模型、检索和文本分析更容易消费。 截至 2026-06-02,GitHub 仓库 microsoft/markitdown 已有约 13.98 万 Star、9500+ Fork,许可证为 MIT。项目地址: 二、它到底做什么MarkItDown 的一句话定位是:一个轻量级 Python 包和命令行工具,用来把各种文件转换成 Markdown。 它目前支持的输入类型包括:
它和传统文档转换工具的侧重点不太一样。MarkItDown 不追求“肉眼看起来和原文件完全一样”,而是更关注“大模型能不能读懂”。因此它会尽量保留文档结构,但输出目标是 Markdown 文本,而不是高保真 HTML 或 PDF。 三、最简单的用法安装可以直接使用 PyPI: 命令行转换一个 PDF:
也可以指定输出文件:
Python 里调用也很直接
如果你只关心 PDF、Word、PPT,可以按需安装可选依赖,避免一次性装全:
四、为什么 Markdown 对大模型友好Markdown 的优势在于“接近纯文本,但仍然有结构”。标题、列表、表格、链接这些信息,都能用很少的标记表达出来。 对大模型来说,这有两个好处:
所以 MarkItDown 更像是“文档进入 AI 系统之前的一道格式网关”。 五、几个值得注意的能力1. 多格式统一入口你可以把 PDF、Office 文档、网页、结构化文本等都转成同一种 Markdown 形态。对企业知识库来说,这意味着后续流水线可以少处理很多格式分支。 2. 插件机制MarkItDown 支持第三方插件,但默认关闭。可以先列出插件:
项目里还提供了 sample plugin,方便开发者扩展自己的转换器。 3. OCR 插件仓库中包含 markitdown-ocr 插件说明:它可以用大模型视觉 从 PDF、DOCX、PPTX、XLSX 中的图片提取文字。用法沿用 MarkItDown 已有的 4. MCP ServerMarkItDown 还有一个 markitdown-mcp 包,可以作为本地 MCP Server 暴露工具 安装和启动很简单: 六、适合哪些场景我认为 MarkItDown 特别适合这几类场景:
七、也要注意安全边界MarkItDown README 里特别强调了安全问题:它会以当前进程权限进行 I/O。也就是说,它能访问当前进程本来就能访问的本地文件、网络资源或数据流。 如果你要在服务端、多人环境或不可信输入场景中使用,至少要注意:
这点很重要。文档转换工具一旦能读文件、拉 URL,就天然可能碰到 SSRF、越权读取、内网访问等风险。 八、我的判断MarkItDown 的价值不在于“又一个 Markdown 转换器”,而在于它抓住了 AI 应用里的一个真实基础设施问题:多格式内容如何稳定进入大模型流水线。 如果你的需求是生成给人看的高保真文档,它未必是最佳选择;但如果你的目标是让模型更好地读取文件、让 RAG 更容易处理资料、让 Agent 有一个通用文件解析入口,那它非常值得放进工具箱。 项目地址: 阅读原文 该文章在 2026/6/3 11:18:57 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886