数据库插入 1000 万数据?别再傻傻用 for 循环了!实测 5 种方式效率对比
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
在日常的后端开发中,我们经常会遇到数据迁移、初始化、或者日志归档等场景,需要向数据库中导入海量数据。 "老板让我往数据库插 1000 万条数据,我写了个 如果你还在用 🛠️ 测试环境与准备为了保证测试的公平性,我们统一测试环境:
1. 🐢 青铜选手:For 循环单条 Insert这是最直观、最容易想到的方式,也是性能最差的方式。 代码示例 (JPA): 原理分析: 实测结果: 2. 🥈 白银选手:JPA 的 saveAll (伪批量)Spring Data JPA 提供了 saveAll 方法,看起来像是批量操作,但真的快吗? 代码示例:
原理分析: 实测结果: 💡 优化 Tip: 3. 🥇 黄金选手:MyBatis 的 foreach 拼接 SQL这是 MyBatis 用户最常用的批量插入方式。 代码示例 (XML):
原理分析: 实测结果: ⚠️ 注意:
4. 💎 钻石选手:原生 JDBC Batch回归本质,使用最底层的 JDBC 批处理。 代码示例:
关键配置: 原理分析: 实测结果: 5. 👑 王者选手:MySQL LOAD DATA INFILE如果说前面的都是在“写代码”,那这个就是在“开挂”。这是 MySQL 官方提供的文件导入命令。 代码示例:
原理分析: 实测结果: 缺点:
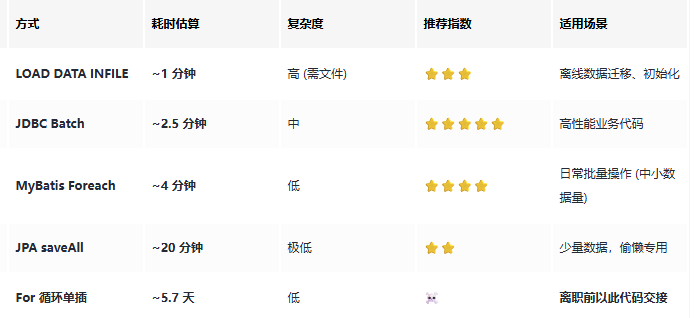
📊 最终排行榜 (1000 万数据估算)
总结与建议
希望这篇文章能帮你避开性能坑,成为团队里的“性能优化大师”! 参考文章:原文链接 该文章在 2026/5/6 9:48:32 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886