必备的数据处理所需的正则表达式
|
admin 2025年7月25日 20:2
本文热度 1224
2025年7月25日 20:2
本文热度 1224
|
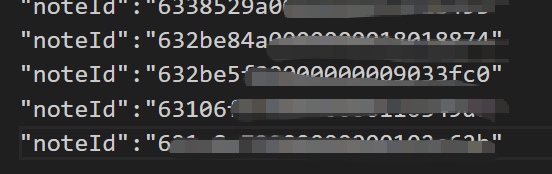
11 5e8be754b95701000138faa*12 5e8bf66cb95701000138fab*19 5ff82fd2c6eec500014*****20 6007f24b4916d700017a4d9*21 600f90ace36e8300019879**49 62973869df10f2000167****
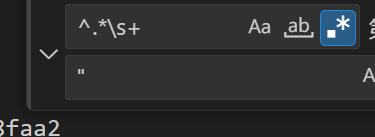
这种是通过 diff 出来的数据,那如何去掉前面多余的:
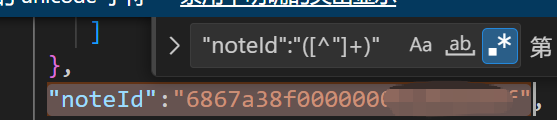
一个大的 json 文件,找到所有 noteId 对应的值的所有行"noteId":"68385178000000002102d**"
如果是在 vscode 里面,我们要批量复制出来所有查找到的:
- 匹配所有结果后,按
Ctrl + Shift + L(Windows)将所有匹配项加入多光标选择。
这样我们就可以从一个大的 json 数据文件里面找到我们要的所有数据,然后新打开一个文件:其他的 key=value 其实也可以参考案例二里面的执行就可以了import retext = """451 681c7b566850f30015a0317*123 abc123xyztest value456"""result = re.sub(r'^.*\s+', '', text, flags=re.MULTILINE)print(result)
re 模块是用于处理正则表达式的标准库,提供了强大的字符串匹配、搜索、替换和分割功能。re.sub(pattern, repl, string, count=0, flags=0)
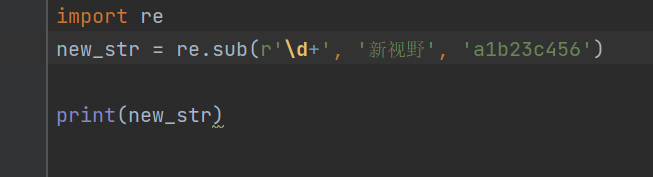
new_str = re.sub(r'\d+', '新视野', 'a1b23c456')print(new_str)
re.split(pattern, string, maxsplit=0, flags=0)
re.finditer(pattern, string, flags=0)
阅读原文:原文链接
该文章在 2025/7/26 9:43:04 编辑过






 400 186 1886
400 186 1886